

Providing an immersive experience to the virtual reality (VR) user has been a long-cherished wish for HCI researchers and developers for decades. Delivering haptic feedback in virtual environments (VEs) is one approach to provide engaging and immersive experiences. In addition to haptic feedback, interaction methods are another aspect that impacts on user experience in the VE. Currently, controllers are the primary interaction method in most VR applications, by indirectly manipulating virtually rendered hands in VR with buttons or triggers. However, hand tracking technology and head mounted displays (HMDs) with a built-in camera enable gesture-based interactions to be a main method in VR applications these days. Hand tracking-based interaction provides a natural and intuitive experience, consistency with real world interactions, and freedom from burdensome hardware, resulting in a more immersive user experience. In this project, we explored the effects of interaction methods and vibrotactile feedback on the user’s experience in a VR game. We investigated the sense of presence, engagement, usability, and objective task performance under three different conditions: (1) VR controllers, (2) hand tracking without vibrotactile feedback, and (3) hand tracking with vibrotactile feedback. The objective of the game is to obtain the highest score by hitting the buttons as accurately as possible with the music. We also developed a device that delivers vibrotactile feedback at the user’s fingertips while hands are tracked by a built-in camera on a VR headset. We observed that hand tracking enhanced the user’s sense of presence, engagement, usability, and task performance. Further, vibrotactile feedback improved the levels of presence and engagement more clearly.


Fluid Echoes is a research and performance project investigating how deep neural networks can learn to interpret dance through human joints, gestures, and movement qualities. This new technology will be immediately applied to allowing dancers to generate and perform choreography remotely as necessitated by the COVID-19 quarantine. Researchers collaborating from their homes across the visual arts (Zach Duer), performing arts (Scotty Hardwig), and engineering (Myounghoon Jeon) at Virginia Tech are working in partnership with the San Francisco-based dance company LEVYdance to build this new platform, funded by the Virginia Tech Institute for Creativity Arts and Technology (ICAT) COVID-19 Rapid Response Grant and LEVYdance.
Virtual reality (VR) is an emerging technology of artistic expression that enables live, immersive aesthetics for interactive media. However, VR-based interactive media are often consumed in a solitary set-up and cannot be shared in social settings. Having a VR-headset for every bystander and synchronizing headsets can be costly and cumbersome. In practice, a secondary screen is provided to bystanders and shows what the VR user is seeing. However, the bystanders cannot have a holistic view this way. To engage the bystanders in the VR-based interactive media, we propose a technique with which the bystanders can see the VR headset user and their experience from a third person perspective. We have developed a physical apparatus for the bystanders to see the VR environment through a tablet screen. We use the motion tracking system to create a virtual camera in VR and map the apparatus’ physical location to the location of the virtual camera. The bystanders can use the apparatus like a camera viewfinder to freely move and see the virtual world through and control their viewpoint as active spectators. We hypothesize that this form of third person view will improve the bystanders’ engagement and immersiveness. Also, we anticipate that the audience members’ control over their POV will enhance their agency in their viewing experience. We plan to test our hypotheses through user studies to confirm if our approach improves the bystanders’ experience. This project is conducted in collaboration with Dr. Sangwon Lee in CS and Zach Duer in Visual Arts, supported by the Institute for Creativity, Arts, and Technology (ICAT).

In this research project, we tie together the beauty in visual art and music by developing a sonification system that maps image characteristics (e.g., salient regions) and semantics (e.g., art style, historical period, feeling evoked) to relevant sound structures. The goal of this project is to be able to produce music that is not only unique and high-quality, but is also fitting to the artistic pieces from which the data were mapped from. To this end, we have interviewed experts from the fields of music, sonification, and visual arts and extracted key factors to make appropriate mappings. We plan to conduct successive empirical experiments with various design alternatives. A combination of JythonMusic, Python and machine learning algorithms has been used to develop the sonification algorithms.
Taking embodied cognition and interactive sonification into account, we have developed an immersive interactive sonification platform, "iISop" at Immersive Visualization Studio (IVS) at Michigan Tech. 12 Vicon cameras around the studio wall track users' location, movement, and gesture and then, the sonification system generates speech, music, and sounds in real-time based on those tracking data. 24 multivisions display visualization of the data. With a fine-tuned gesture-based interactive sonification system, a performing artist (Tony Orrico) made digitalized works on the display wall as well as penwald drawings on the canvas. Users can play the piano by hopping with a big virtual piano that responds to their movements. We are also conducting artistic experiments with robots and puppies. Currently, we are focusing on making more accessible mapping software between motion and sound, and a portable version of this motion tracking and sonification system. Future works include implementing natural user interfaces and a sonification-inspired story-telling system for children. This project has been partly supported by the Department of Visual and Performing Arts at Tech, the International School of Art & Design at Finlandia University, and the Superior Ideas Citemd Funding.
* iISoP comes from a Greek writer, Aesop.


Traditionally, dancers choreograph based on music. On the contrary, the ultimate goal of this project is to have dancers improvise music and visuals by their dancing. Dancers still play an expected role (dance), but simultaneously integrate unexpected roles (improvise music and visuals). From the traditional perspective, this might embarrass dancers and audience, but certainly adds aesthetic dimensions to their work. In this project, we adopted emotions and affect as the medium of communication between gestures and sounds. To maximize affective gesture expression, expert dancers have been recruited to dance, move, and gesture inside the iISoP system while being given both visual and auditory outputs in real time. A combination of Laban Movement Analysis and affective gesturing was implemented for the sonification parameter algorithms.
The recent dramatic advance of machine learning and artificial intelligence has also propelled robotics research into a new phase. Even though it is not a main stream of robotics research, robotic art is getting more widespread than ever before. In this design research, we have designed and implemented a novel robotic art framework, in which human dancers and drones can collaboratively create visualization and sonification in the immersive virtual environment. This dynamic, intermodal interaction will open up a new potential for novel aesthetic dimensions.

There was a tragic accident of sinking a ferry in Korea in April 16, 2014. We aim to remember this tragedy together to support people who lost their family in the accident and let more people know about it for prompt resolution of this matter. Artists and scholars have tried to show their support for family by performances and writings. In the same line, we have created a real-time tweet sonification program using “#416”, the date of the tragedy. The text of tweets including #416 is translated into the Morse code and sonified in real-time.
To add a novel value (i.e., value-added design) to the electronic devices (e.g., home appliances, mobile devices, in-vehicle infotainment, etc.), we have designed various auditory displays (e.g., auditory icons, earcons, spearcons, spindexes, etc.). The design process involves not only cognitive mappings (from the human factors perspectives), but also affective mappings (from the aesthetics and pleasantness perspectives). We have also developed new sound-assessment methodologies such as the Sound Card Sorting and Sound-Map Positioning. Current projects include the design of Auditory Emoticons and Lyricons (Lyrics + Earcons). Based on these diverse experiences, we will continue to conduct research on this auditory display designs to create more fun and engaging products as well as effective and efficient products.

A major component of the U.S. Department of Transportation’s (DOT) mission is to focus on pedestrian populations and how to enable safe and efficient mobility for vulnerable road users. However, evidence states that college students have the highest rate of pedestrian accidents. Due to the excessive use of personal listening devices (PLDs), vulnerable road users have begun subjecting themselves to reduced levels of achievable situation awareness resulting in risky street crossings. The ability to be aware of one’s environment is critical during task performance; however, the desire to be self-entertained should not interfere or reduce one’s ability to be situationally aware. The current research seeks to investigate the effects of acoustic situation awareness and the use of PLDs on pedestrian safety by allowing pedestrians to make “safe” vs. “unsafe” street crossing within a simulated virtual environment. The outcomes of the current research will (1) provide information about on-campus vehicle and pedestrian behaviors, (2) provide evidence about the effects of reduced acoustic situation awareness due to the use of personal listening devices, and (3) provide evidence for the utilization of vehicle-to-pedestrian alert systems. This project is conducted in collaboration with Dr. Rafael Patrick (ISE), supported by the Center for Advanced Transportation Mobility and ICAT.


Automakers have announced that they will produce fully automated vehicles in near future. However, it is hard to know when we can use the fully automated vehicles in our daily lives. What would be the infotainment in the fully automated vehicles? Are we going to have a steering wheel and pedals? To make a blueprint of the futuristic infotainment system and user experience in the fully automated vehicles, we investigate user interface design trends in industry and research in academia. We also explore user needs from young drivers and domain experts. With some use cases and scenarios, we will suggest new design directions for futuristic infotainment and user experience in the fully automated vehicles. This project is supported by our industry partner.
The objective of the proposed research is to investigate the potential of various types of in-vehicle intelligent agents in the context of automated driving. The role of the agents is to provide driving-related information so that the driver can notice the intention and status of the automated driving system, which will influence the driver’s perception about the automated vehicle system and develop the level of trust towards it. To explore more specific design guidelines, we explore various characteristics of the agents, such as embodiment, information type, speech style, emotion, personality, attitude, gesture, etc. This project is supported by the Northrop Grumann Undergraduate Research Experience Award.


In addition to the traditional collision warning sounds and voice prompts for personal navigation devices, we are devising more dynamic in-vehicle sonic interactions in automated vehicles. For example, we design real-time sonification based on driving performance data (i.e., driving as instrument playing). To this end, we make mappings between driving performance data (speed, lane deviation, torque, steering wheel angle, pedal pressure, crash, etc.) with musical parameters. In addition, we identify situations in which sound can play a critical role to provide better user experience in automated vehicles (e.g., safety, trust, usability, situation awareness, or novel presence). This project is supported by our industry partner.
Vehicle automation is becoming more widespread. As automation increases, new opportunities and challenges have also emerged. Among various new design problems, we aim to address new opportunities and directions of auditory interactions in highly automated vehicles to provide better driver user experience and to secure road safety. Specifically, we are designing and evaluating multimodal displays for hand-over/take-over procedure. In this project, we collaborate with Kookmin University and Stanford University. This project is supported by the Korea Automobile Testing and Research Institute.


Investigating driving behavior using a driving simulator is widely accepted in the research community. Recently, railroad researchers have also started conducting rail-crossing research using the driving simulator. Whereas using the simulator has a number of benefits, the validation of the simulated research still remains to be addressed further. To this end, we are conducting research by comparing the simulated driving behavior with the naturalistic driving behavior data. This project is supported by Federal Railroad Administration under US DOT.
One of the potential approaches to reducing grade crossing accidents is to better understand the effects of warning systems at the grade crossings. To this end, we investigate drivers' behavior patterns (e.g., eye-tracking data and driving performance) with different types of warnings when their car approaches the grade crossings. Particularly, we design and test in-vehicle auditory alerts to make passive crossings into active crossings. We also plan to examine the effects of in-vehicle distractors (phone-call, radio, etc.) on their warning perception and behavior change. Based on these empirical data, we will improve our warning system design and make standardized design guidelines. This project has been supported by Michigan DOT, US DOT (Department of Transportation), and FRA (Federal Railroad Administration).
The goal of this project is to increase driver safety by taking drivers’ emotions and affect into account, in addition to cognition. To this end, we have implemented a dynamic real-time affect recognition and regulation system. At the same time, in order for the system to accurately detect a driver’s essential emotional state, we have identified a driving-specific emotion taxonomy. Using driving simulators, we have demonstrated that specific emotional states (e.g., anger, fear, happiness, sadness, boredom, etc.) have different impacts on driving performance, risk perception, situation awareness, and perceived workload. For affective state detection, we have used eye-tracking, facial expression recognition, respiration, heart rate (ECG), brain activities (fNIRS), grip strength detection, and smartphone sensors, etc. For regulation part, we have been testing various music pieces (e.g., emotional music, self-selected music), sonification (e.g., real-time sonification based on affect data), and the speech-based systems (e.g., emotion regulation prompt vs. situation awareness prompt). Part of this project is supported by Michigan Tech Transportation Institute and Korea Automobile Testing and Research Institute.
In-vehicle touchscreen displays offer many benefits, but they can also distract drivers. We are exploring the potential of gesture control systems to support or replace potential dangerous touchscreen interactions. We do this by replacing information which we usually acquire visually with auditory displays that are both functional and beautiful. In collaboration with our industry partner, our goal is to create an intuitive, usable interface that improves driver safety and enhances the driver experience. This project was supported by Hyundai Motor Company.

The Auditory Spatial Stroop experiment investigates whether the location or the meaning of the stimuli more strongly influences performance when they conflict with each other. For example, the word “LEFT” or “RIGHT” is presented in a congruent or incongruent position from its meaning. It can be easily applied to the complex driving environment. For example, the navigation device tells you to turn right, but the collision avoidance system warns you that a hazard is coming from right at the same time. How should we respond to this conflicting situation? To explore this problem space further, we conduct Auditory Spatial Stroop research using OpenDS Lane Change Test to investigate how driving behavior varies under different multimodal cue combinations (visual, verbal, & non-verbal; temporally, spatially, semantically congruent & incongruent).
The goal of this project is to understand driver emotion from comprehensive perspective and help emotional drivers mitigate the effects of emotions on driving performance. Our empirical research has shown that happy music and self-selected music can help angry drivers drive better. However, self-selected "sad" music might degenerate driving performance. This research has also shown the potentials of using fNIRS and ECG to monitor drivers' affective states.

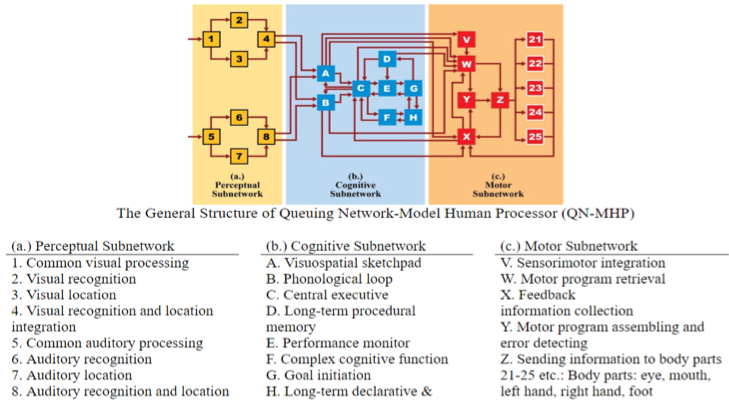
There have been many studies on investigating appropriate auditory displays for takeover request. However, most of them were examined through empirical human subject research. In the present study, we established computational models using a Queuing Network Model Human Processor (QN-MHP) framework to predict a driver’s reaction time to auditory displays for takeover requests. The reaction times for different sound types were modeled based on the results of subjective questionnaires, acoustical characteristics of sounds and empirical results from the previous findings. The current models will be expanded to span more factors and different contexts. This study will contribute to driving research and auditory display design by allowing us to simulate and predict driver behavior with varying parameters. This project is conducted in collaboration with Dr. Yiqi Zhang in Penn State University. * The QN-MHP framework represents the human cognition system as a queuing network based on several similarities to brain activities. QN-MHP consists of three subnetworks: perceptual, cognitive, and motor subnetworks.

People with autistic spectrum disorders are known to have three major issues - impairment of social relationships, social communication, and imaginative thought. The first two problems have a common element, "social interaction with people". Literature has shown that people with autism are likely to interact with computers and animals rather than humans because they are basically simpler than humans. Recent research also shows that using interactive robots might facilitate their social interaction. In this line, we have adopted a small iOS-based interactive robot, "Romo" as our research platform and developed an emotional interaction platform for children with autism. Based on our facial expression detection (client) and sonification server systems, we are creating a social interaction game. In addition, we use multiple Kinects in the room and oversee the overall interaction scene (e.g., distance, turn-taking, chasing, etc.). This project is supported by NIH (National Institutes of Health) via the NRI (National Robotics Initiative) program.
The trend to integrate art and science is pervasive in formal education. STEM education is evolving into STEAM (Science, Technology, Engineering, Art, and Math) movement by adding art and design to the equation. We have tried to develop STEAM education programs, specifically, for underrepresented students in a rural area, including female students, students from low income families, and students with various disabilities. Fairly recently, we have been developing a new afterschool program with a local elementary school entitled, "Making Live Theatre with Multiple Robots as Actors". In this program, students are expected to learn and ponder about (1) technology and engineering (e.g., computational thinking); (2) art and design (e.g., writing, stage designing, preparing music); (3) collaboration (e.g., discussing, role allocating); and (4) co-existence with robots (e.g., philosophical and ethical questions about the roles and limitations of robots).


As the influence of social robots in people’s daily lives continues to grow, research has been conducted on understanding people’s perception about robots’ characteristics, including sociability, trust, acceptance, and preference. Among many variables, we have focused on factors that influence user perception on robots’ emotive expressions. Robots’ facial expressions, voice (speech), body language, and posture have been considered and we have integrated multiple facets of user perception on robots during a conversational task by varying the robot types, emotions, facial expressions, and voice types. The results will provide a design guideline for emotional and trustworthy robots, especially employing emotive expressions and facilitate the relationship between people and social robots such as assistive robots, voice assistants, and any other conversational agents. This project is supported by the Northrop Grumann Undergraduate Research Experience Award.
Affect detection systems are a great means of procuring direct feedback for a system by tracking the user’s reactions. In this case, the facial affect detection system monitors the facial expression of users and detects the emotion displayed. Visualization of emotions detected can aid in making informed decisions. It can be applied to study the effects of the system on the user and alter the behavior of the system accordingly. For instance, the visualizations of a system where a robot is interacting with a child can be monitored in order to change the course of robot action according to the insights gained from monitoring the emotions of the child during the course of interaction.
The Smart Exercise application is an Android application paired with a wearable Bluetooth IMU sensor that is designed to provide real-time auditory and visual feedback on users’ body motion, while simultaneously collecting kinematic data on their performance. The application aims to help users improve physical and cognitive function, improve users’ motivation to exercise, and to give researchers and physical therapists access to accurate data on their participants’ or patients’ performance and completion of their exercises without the need for expensive additional hardware.
Performing independent physical exercise is critical to maintain one's good health. However, it is hard specifically for people with visual impairments to do exercise without proper guidance. To address this problem, we have developed a Musical Exercise platform using Microsoft Kinect for people with visual impairments. With the help of audio feedback of Musical Exercise, people with visual impairments can perform exercises in a good form consistently. Our empirical assessment shows that our system is a usable exercise assistance system. The results also confirm that a specific sound design (i.e., discrete) is better than the other sound or no sound at all.

Many outdoor navigation systems for visually impaired people are already out there. However, a few attempts have been made to enhance their indoor navigation. Think about your blind friends when they attend the conference and stay at a hotel. They might not be familiar with all the layout of the new room and the entire hotel. We have interviewed visually impaired people and identified current problems and plausible issues. Based on that, we have designed and developed indoor navigation system, called "Personal Radar" using an ultrasonic belt (as an object detection technology) and tactile and auditory feedback (as a display technology). For the next version, we are looking at the application of a new lidar system.

Brain-computer interfaces are one of the hot topics in novel interaction design. We test an EEG (EPOC) device to identify whether we can effectively and efficiently use it as a monitoring and controlling tool. Brain waves can be one of the many signals to provide information about users' states (e.g., arousal, fatigue, workload, or emotions). Moreover, we can have people (those with disabilities or their hands occupied) control interfaces using an EEG device. We also have a plan to use it as a composing tool. In the iISoP platform, we will improvise harmonized music based on our body (based on movement tracking data) and mind (based on brainwave data). In addition, we investigate users' cognitive and affective states using fNIRS (functional Near-infrared spectroscopy), EEG, ECG, and EMG when they conduct a novel task (e.g., novel interfaces), an emotional task (e.g., seeing or hearing emotional stimuli), or dual tasks. Based on these experiments, we would also identify the relationship between cognitive processes and affective processes.
Based on well-formulated methodologies in psychology and human factors and professional design experience of automotive user interfaces, we further explore the next generation in-vehicle interfaces and services in terms of driving performance, safety, and user (driver and passengers) experiences. For example, we investigate the possibility of the use of subliminal cues (e.g., faint light, soft sounds, scent, tactile feedback, etc.) for drivers. To more actively explore the next generation in-vehicle interfaces, we have hosted a series of workshops (e.g., AutomotiveUI, UBICOMP, ICAD, Persuasive Tech, etc.) and edited journal special issues (e.g., Pervasive and Mobile Computing and MIT Presence: Teleoperators and Virtual Environments). This project is supported by Michigan Tech Transportation Institute Initiative Funding.
